
안녕하세요!
데이터 분류하기 2 본문
https://shinyfood.tistory.com/85
머신러닝 training & test
훈련과 검증 테스트데이터 분류 - 정의된 변수 이름은 없음 - 훈련데이터 : 훈련(fit)에 사용되는 데이터 : (훈련 독립변수) train_input, train_x, X_train : (훈련 종속변수) train_target, train_y, y_train - 검증
shinyfood.tistory.com
해당글과 이어집니다.
print(fish_length, fish_weight)
[25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0,
30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0,
33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0,
36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2,
12.4, 13.0, 14.3, 15.0] [242.0, 290.0, 340.0, 363.0,
430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0,
575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0,
850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4,
12.2, 19.7, 19.9]2차원 데이터 생성하기 // numpy에서 column_stack은 튜플로 묶어 넣어주면 zip처럼 리스트로 변환해준다.
fish_data = np.column_stack((fish_length, fish_weight))
fish_data
1차원 데이터 생성하기 // 튜플로 만들고 ones와 zeros를 사용하면 1이 35개 0이 14개 나온다. 그것을 concatenate 를 사용하면 합쳐진다.
fish_target = np.concatenate((np.ones(35),np.zeros(14)))
fish_target
(array([[ 25.4, 242. ], [ 26.3, 290. ], [ 26.5, 340. ], [ 29. , 363. ],
[ 29. , 430. ], [ 29.7, 450. ], [ 29.7, 500. ], [ 30. , 390. ],
[ 30. , 450. ], [ 30.7, 500. ], [ 31. , 475. ], [ 31. , 500. ],
[ 31.5, 500. ], [ 32. , 340. ], [ 32. , 600. ], [ 32. , 600. ],
[ 33. , 700. ], [ 33. , 700. ], [ 33.5, 610. ], [ 33.5, 650. ],
[ 34. , 575. ], [ 34. , 685. ], [ 34.5, 620. ], [ 35. , 680. ],
[ 35. , 700. ], [ 35. , 725. ], [ 35. , 720. ], [ 36. , 714. ],
[ 36. , 850. ], [ 37. , 1000. ], [ 38.5, 920. ], [ 38.5, 955. ],
[ 39.5, 925. ], [ 41. , 975. ], [ 41. , 950. ], [ 9.8, 6.7],
[ 10.5, 7.5], [ 10.6, 7. ], [ 11. , 9.7], [ 11.2, 9.8],
[ 11.3, 8.7], [ 11.8, 10. ], [ 11.8, 9.9], [ 12. , 9.8],
[ 12.2, 12.2], [ 12.4, 13.4], [ 13. , 12.2], [ 14.3, 19.7],
[ 15. , 19.9]]),
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]))데이터 섞으면서 분류하기
랜덤하게 섞으면서 두개(훈련 : 테스트)의 데이터로 분류해주는 train_test_split을 사용하자.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target =train_test_split(fish_data, fish_target,
test_size=0.3, random_state=42,
stratify = fish_target)
print(f"{train_input.shape},{train_target.shape},{test_input.shape},{test_target.shape}")
(34, 2),(34,),(15, 2),(15,)모델(클래스) 생성하기
kn = KNeighborsClassifier(n_neighbors=5)
모델 훈련 시키기
kn.fit(train_input, train_target)
훈련 정확도 확인하기
train_score = kn.score(train_input, train_target)
검증 정확도 확인하기
test_score = kn.score(test_input, test_target)
과대적합 : 훈련 > 검증 또는 훈련이 1인 경우
과소적합 : 훈련 < 검증 또는 검증이 1인 경우
과소적합이 일어나는 모델은 사용할 수 없음.
과대적합 중에 훈련 정확도가 1인 경우의 모델은 사용할 수 없음
과대적합이 보통 0.1 이상의 차이를 보이면 정확도의 차이가 많이 난다고 의심해 볼수 있음.
모델 선정 기준 : 과소적합이 일어나지 않으면서,
: 훈련 정확도가 1이 아니고,
: 훈련과 검증의 차이가 0.1 이내인 경우
선정된 모델을 "일반화 모델"이라고 칭합니다.
다만, 추가로 선정 기준 중에 평가기준이 있음.
가장 바람직한 결과는 훈련 > 검증 > 테스트
(훈련 > 검증 < 테스트인 경우도 있음.)매우매우매우매우매우 중요하다.
이후 지난 글처럼 이웃의 숫자를 찾아준다.
### 1보다 작은 가장 좋은 정확도일 때의 이웃의 개수 찾기
### 모델 클래스 생성
kn = KNeighborsClassifier()
### 훈련시키기
kn.fit(train_input, train_target)
### 1보다 작은 가장 좋은 정확도일 때의 이웃의 개수 찾기
# - 반복문 사용 : 범위는 3~ 전체 데이터 개수
### 정확도가 가장 높을 때의 이웃 개수를 담을 변수
nCnt = 0
### 정확도가 가장 높을때의 값을 담을 변수
nScore = 0
for n in range(3, len(train_input), 2) :
kn.n_neighbors = n
score = kn.score(train_input, train_target)
print(f"{n} / {score}")
### 1보다 작은 정확도인 경우..
if score < 1 :
### nScore의 값이 score보다 작은 경우 담기
if nScore < score :
nScore = score
nCnt = n
print(f"nCnt = {nCnt}, nScore={nScore}")
### 모델의 성능이 가장 좋은 시점의 이웃의 개수를 추출하기 위한
# 하이퍼파라메터 튜닝 결과, 이웃의 개수 19개를 사용했을 때,
# 가장 좋은 성능을 발휘하는것으로 확인됨.3 / 1.0
5 / 1.0
7 / 1.0
9 / 1.0
11 / 1.0
13 / 1.0
15 / 1.0
17 / 1.0
19 / 1.0
21 / 0.7058823529411765
23 / 0.7058823529411765
25 / 0.7058823529411765
27 / 0.7058823529411765
29 / 0.7058823529411765
31 / 0.7058823529411765
33 / 0.7058823529411765
nCnt = 21, nScore=0.7058823529411765
임의 데이터로 테스트
dist, indexes = kn.kneighbors([[25,150]])
indexes
array([[29, 16, 26, 0, 11, 9, 6, 21, 23, 19, 30, 14, 32, 8, 27, 12,
10, 3, 17, 1, 4, 22, 2, 31, 15, 28, 24, 7, 5, 25, 20, 18,
33]], dtype=int64)plt.scatter(train_input[:,0], train_input[:, 1] , c="red", label="fish")
plt.scatter(25,150, marker="^", c="green", label="pred")
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], c="blue", label="nei")
plt.xlabel("length")
plt.ylabel("weight")
plt.title("FISH", fontsize=20, fontweight=10)
plt.legend()
plt.show()
예측 결과는 빙어로 확인되었으나,
시각적으로 확인하였을 때는 도미에 더 가까운 것으로 확인됨.
실제 이웃을 확인한 결과 빙어쪽 이웃을 모두 사용하고 있음
→ 이런 현상이 발생한 원인 : 스케일(x축과 y축의 단위)이 다르기 때문에 나타나는 현상
→ "스케일이 다르다" 라고 표현합니다.
해소방법 : 데이터 정규화 전처리를 수행해야함.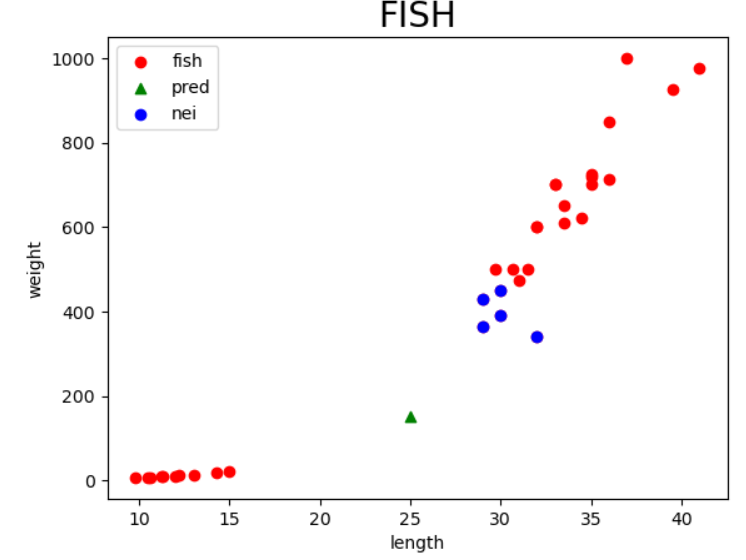
사용된 이웃 확인하기
앞의 array는 거리값.
뒤의 array는 index
kn.kneighbors([[25,150]])
(array([[130.48375378, 130.73859415, 138.32150953, 138.39320793,
140.80142045, 140.87753547, 141.96260071, 143.23581954,
143.7232062 , 144.10388614, 190.12890364, 213.03755537,
240.05207768, 280.02856997, 300.04166377, 325.0553799 ,
350.03155572, 350.04641121, 350.06035194, 450.05444115,
450.05444115, 460.07852591, 470.09600083, 500.07224478,
550.05817874, 550.05817874, 550.09090158, 564.1072593 ,
570.08771255, 575.08694995, 700.08642324, 775.13563329,
825.15513693]]),
array([[29, 16, 26, 0, 11, 9, 6, 21, 23, 19, 30, 14, 32, 8, 27, 12,
10, 3, 17, 1, 4, 22, 2, 31, 15, 28, 24, 7, 5, 25, 20, 18,
33]], dtype=int64))정규화하기
앞서 스케일이 다른것을 확인했기 때문에 정규화를 진행하여 값을 맞춰준다
정규화 → 표준점수화
표준점수 = (각 데이터 - 데이터 전체 평균) / 데이터 전체 표준편차
표준점수 : 각 데이터가 원점(0)에서 표준편차 만큼 얼마나 떨어져 있는지를 나타내는 값
데이터 전체 표준편차 구하기
std = np.std(train_input, axis=0)
std
array([ 10.0816099 , 319.21122132])
정규화(표준점수) 처리하기
train_scaled = (train_input - mean) / std
train_scaled
array([[-1.4703534 , -1.35773091],
[ 0.49361864, 0.48368306],
[ 0.74159491, 0.54633749],
......
[ 0.29523763, -0.17418855],
[ 1.38633321, 1.65845379]])
plt.scatter(train_scaled[:,0], train_scaled[:, 1] , c="red", label="fish")
plt.scatter(25,150, marker="^", c="green", label="pred")
plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], c="blue", label="nei")
plt.xlabel("length")
plt.ylabel("weight")
plt.title("FISH", fontsize=20, fontweight=10)
plt.legend()
plt.show()
예측값 스케일을 맞추자
new = ([25,150] - mean) / std
new
array([-0.20071491, -0.92604182])
plt.scatter(train_scaled[:,0], train_scaled[:, 1] , c="red", label="fish")
plt.scatter(new[0],new[1], marker="^", c="green", label="pred")
plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], c="blue", label="nei")
plt.xlabel("length")
plt.ylabel("weight")
plt.title("FISH", fontsize=20, fontweight=10)
plt.legend()
plt.show()

정규화가 진행된 이후에 그래프를 다시 그려보면
모델(클래스) 생성하기
kn = KNeighborsClassifier()
모델 훈련하기
kn.fit(train_scaled, train_target)
모델(클래스) 생성하기
kn = KNeighborsClassifier()
모델 훈련하기
kn.fit(train_scaled, train_target)
1.0
테스트 데이터로 검증하기(평균과 표준편차는 훈련에서 사용한 값을 그대로 사용한다.)
- 검증 또는 테스트 데이터를 스케일링 정규화 처리
- 이때는 훈련에서 사용한 mean과 std를 그대로 사용해야 함.
test_scaled = (test_input - mean) / std
test_score = kn.score(test_scaled, test_target)
test_score
1.0
예측하기
- 2차원으로 만들어줘야함.
kn.predict([new])
array([1.])
이웃 확인하고 시각화 하기
dist, indexes = kn.kneighbors([new])
indexes
array([[14, 32, 30, 8, 27]], dtype=int64)plt.scatter(train_scaled[:,0], train_scaled[:, 1] , c="red", label="fish")
plt.scatter(new[0],new[1], marker="^", c="green", label="pred")
plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], c="blue", label="nei")
plt.xlabel("length")
plt.ylabel("weight")
plt.title("nei nei FISH", fontsize=20, fontweight=10)
plt.legend()
plt.show()
'개발일지 > ML(Machine Learning),DL(Deep Learning)' 카테고리의 다른 글
| 신경망계층_추가방법_및_성능향상방법(2) (4) | 2024.01.08 |
|---|---|
| deep learning / DNN 분류데이터 사용(실습) (2) | 2024.01.05 |
| 신경망 계층 추가법 및 성능향상법 (1) (1) | 2024.01.04 |
| ML/ 앙상블 모델(1) (2) | 2023.12.27 |
| 머신러닝 training & test (2) | 2023.12.22 |



