
안녕하세요!
데이터분석 교통데이터 수집 및 가공(1) 본문
이 게시물의 내용은 <포항시 BIS 교통카드 사용내역 데이터 수집>에서 데이터를 받아 사용했습니다.
URL : 국가교통 데이터 오픈마켓
오늘도 시작은 pandas를 import하며 시작한다.
import pandas as pd
위에 언급한것처럼 포항시 BIS 교통카드 사용내역 데이터 수집을 하여, 1건의 데이터파일을 처리하는법을 알아보자.
file_path = "./01_data/org/trfcard(0)/trfcard.csv"
df_bus_card_org = pd.read_csv(file_path)
df_bus_card_org.head(1)먼저 원래 했듯, 파일의 경로를 지정해주고 pandas를 이용하여 파일을 열어준다.
이후 맨윗줄(python은 0부터시작하므로 데이터가있는 첫번째줄을 맨윗줄이라 하였다)을 조회해보자.

이제 데이터의 결측과 이상을 체크해보자. 잊어서는 안되는 작업이다.
df_bus_card_org.info()
16185 entries, 0 to 16184로 문제가 없어보이지만, 5번째행인 4번행의 데이터가 무언가 문제가 있음을 확인 할 수 있다. 왜 저기만 16164인것인가? 나이타입의 문제가 조금 있을지도 모름을 유의하고 데이터를 보도록 하자.
df_bus_card_org.info()
이상치에서는 따로 특별히 튀는 값이 없는것으로 보아 멀쩡하다는 사실을 확인했다.
컬럼을 조회했을때, 영어로 표현돼있는 컬럼들이 우리의 눈에 익숙하지 않으니 먼저 한글화를 해주도록 하자.

file_path = "./01_data/org/trfcard(0)/trfcard_columns.xlsx"
df_bus_card_col_org = pd.read_excel(file_path,
header=2,
usecols="B:C")
df_bus_card_col_org.head(1)우리가 필요한건 컬럼명 (영문) 과 컬럼명 (한글) 이기때문에 header에서 세번째줄인 2와 B,C 열을 가져왔다.
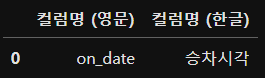
### 컬럼명의 이름을 매핑하여 변경하기 위해서는
# - 컬럼정의 값을 key : value 딕셔너리 타입으로 정의해야함.
# 예시 : {영문명 : 한글명, 영문명 : 한글명, ... }
### df_bus_card_col_org의 데이터를 딕셔너리로 변환하기
# - iloc[행, 열] i index loc location : 인덱스 번호를 이용하는 방식
# - for 문에서는 iloc를 많이 쓴다.
print(df_bus_card_col_org.iloc[0, 0])
print(df_bus_card_col_org.iloc[0, 1])
print(df_bus_card_col_org.iloc[1, 0])
print(df_bus_card_col_org.iloc[1, 1])
print("----------------------------")
# - loc[행값, 열값] : 인덱스 값을 이용하는 방식
print(df_bus_card_col_org.loc[0, "컬럼명 (영문)"])
print(df_bus_card_col_org.loc[0, "컬럼명 (한글)"])on_date
승차시각
off_date
하차시각
----------------------------
on_date
승차시각여기서 iloc와 loc는 정말 많이쓰이니까 알아두도록하자.
중간에도 쓰여있지만 i loc는 Index Location이고 loc는 Location이다.
대괄호 안에는 행과 열이 들어간다. [0,0]은 첫번째행의 첫번째열 [0,1]은 첫번째행의 두번째열을 의미한다.
df_bus_card_col_org 데이터프레임을 딕셔너리로 변환
- 딕셔너리 변수명 : df_bus_card_col_new_dict
- 영문명은 key로, 한글명은 value로 만들어주세요.
여러가지 방법이 사용 가능하다. 그 중 2가지 방법을 알아보도록 하자.
df_bus_card_col_new_dict = {}
for i in range(len(df_bus_card_col_org)):
key = df_bus_card_col_org.iloc[i, 0]
value = df_bus_card_col_org.iloc[i, 1]
df_bus_card_col_new_dict[key] = value첫번째 방법은 우선 변수명을 딕셔너리로 선언 한 뒤, 길이만큼 반복해준다. iloc에서 key값과 value값을 이용하여 입력해준다.
df_bus_card_col_new_dict = {}
for k, v in zip(df_bus_card_col_org.iloc[:,0], df_bus_card_col_org.iloc[:,1]) :
print (k, v)
df_bus_card_col_new_dict[k] = v두번째방법은 변수명 선언 뒤 k, v로 각각 넣어주는것이다.
나는 첫번째 방법을 사용했다. 편한방법을 사용하도록 하자.
{'on_date': '승차시각',
'off_date': '하차시각',
'route_name': '노선명',
'descr': '노선설명',
'age_type': '승객연령',
'trans_yn': '환승여부',
'addfee_yn': '추가운임여부',
'start_bstop': '승차정류장',
'start_gps_x': '승차정류장 GPS X',
'start_gps_y': '승차정류장 GPS Y',
'end_bstop': '하차정류장',
'end_gps_x': '하차정류장 GPS X',
'end_gps_y': '하차정류장 GPS Y'}
이제 컬럼명을 변경한 모습을 보았으니 한번 다시 확인해보자!

이상하게도 아직 적용이 되지 않은 모습이다. 왜일까?
왜냐하면 메모리에 반영하지 않았기 때문이다. 딕셔너리로 변환하면서 새로운 주소에 새로운 값이 생긴것을 보여줬을뿐, 실제로 기존 메모리에 올라간것에 반영되지 않았기 때문이다.
여기서도 바꾼 이름을 적용시키는 두가지 방법이 존재한다.
1. df_bus_card_org = df_bus_card_org.rename(columns=df_bus_card_col_new_dict)
2. df_bus_card_org.rename(columns=df_bus_card_col_new_dict, inplace = True)
# - inplace = True : 변경사항을 메모리에 반영하기.
1번을 사용할 경우, 우리가 dictionary로 만든 주소를 우리가만들어준 변수가 바라보게 하는 방법이다.
2번을 사용할 경우는 현재 가지고있는 주소의 값을 우리가 만든 값으로 변경하는 방법이다.
이것 또한 자유롭게 사용하길 바란다.
분석을 위한 데이터 가공하기
<분석 주제>
- 대주제 : 포항시 버스 이용량 분석
- 소주제
(버스 이용량 분석)
* 기준월 및 기준일자별 버스 이용량 분석 비교
* 기준일 및 시간대별 버스 이용량 분석 비교
* 기준시간 및 시간(분)별 버스 이용량 분석 비교
(버스 내 체류시간 분석)
* 기준월 및 기준일자별 버스 체류시간 분석 비교
* 기준일 및 시간대별 버스 체류시간 분석 비교
* 기준시간 및 시간(분)별 버스 체류시간 분석 비교
* 승하차정류장 구간별 법스 내 체류시간
- 체류시간(분) 상위 30건 분석 비교
지난 게시물에서도 확인했던 copy를 이용하여 데이터프레임 복제하자. (원본 데이터를 유지하기 위함)
df_bus_card_kor = df_bus_card_org.copy()
위에서 확인할때 승 하차 시각이 int값임을 확인했다. 아마 위로 올라가서 보면 info에 int가 있는걸 볼 수있을것이다.
우리는 date타입으로 바꾸기위해 우선 문자타입으로 바꾸도록 하자.
astype() : 데이터 형변환 함수
df_bus_card_kor = df_bus_card_kor.astype({"승차시각" : "str",
"하차시각" : "str"})
df_bus_card_kor.info()astype을 이용하면 데이터의 형 변환을 할 수 있다. int타입에서는 바로 date타입으로 갈 수 없으므로 str타입을 거치는것에 유의하자.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16185 entries, 0 to 16184
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 승차시각 16185 non-null object
1 하차시각 16185 non-null object
2 노선명 16185 non-null object
3 노선설명 16185 non-null object
4 승객연령 16164 non-null object
5 환승여부 16185 non-null object
6 추가운임여부 16185 non-null object
7 승차정류장 16185 non-null object
8 승차정류장 GPS X 16185 non-null float64
9 승차정류장 GPS Y 16185 non-null float64
10 하차정류장 16185 non-null object
11 하차정류장 GPS X 16185 non-null float64
12 하차정류장 GPS Y 16185 non-null float64
dtypes: float64(4), object(9)
memory usage: 1.6+ MBint → object 로 변한걸 확인 할 수 있다.
이제 우리가 필요한 정보들을 따로 분리해서 보도록 하자.
df_bus_card = df_bus_card_kor
[["승차시각", "하차시각", "승객연령", "환승여부", "추가운임여부", "승차정류장", "하차정류장"]].copy()
df_bus_card.head()
df_bus_card에 다시 카피한 뒤 head만 조회했다.
df_bus_card.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16185 entries, 0 to 16184
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 승차시각 16185 non-null object
1 하차시각 16185 non-null object
2 승객연령 16164 non-null object
3 환승여부 16185 non-null object
4 추가운임여부 16185 non-null object
5 승차정류장 16185 non-null object
6 하차정류장 16185 non-null object
dtypes: object(7)
memory usage: 885.2+ KB
승차시각과 하차시각 데이터 타입을 날짜타입으로 변환하기
df_bus_card["승차시각"] = pd.to_datetime(df_bus_card_kor.loc[:,"승차시각"])
df_bus_card["하차시각"] = pd.to_datetime(df_bus_card_kor.loc[:,"하차시각"])
df_bus_card.info()
날짜타입으로 변환할때는 pandas에서 to_datetime을 사용했다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16185 entries, 0 to 16184
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 승차시각 16185 non-null datetime64[ns]
1 하차시각 16185 non-null datetime64[ns]
2 승객연령 16164 non-null object
3 환승여부 16185 non-null object
4 추가운임여부 16185 non-null object
5 승차정류장 16185 non-null object
6 하차정류장 16185 non-null object
dtypes: datetime64[ns](2), object(5)
memory usage: 885.2+ KB이쁘게 잘 바뀌었다.
우리의 목표중 하나인 체류시간을 위해 체류시간(분) 계산 및 컬럼을 생성하도록 하자.
round((df_bus_card.iloc[0, 1] - df_bus_card.iloc[0, 0]).total_seconds()/60,2)7.92round()내의 타입이 DataFrame이므로 .total_second()만 사용해도 잘 되는것을 확인했으니 모든 열에 적용하도록 하자.
round((df_bus_card["하차시각"] - df_bus_card["승차시각"]).dt.total_seconds()/60,2)해당 round()의 경우는 DataFrame이 아니여서 dt.total_seconds가 필요하다.
0 7.92
1 32.18
2 3.68
3 34.48
4 4.48
...
16180 13.65
16181 2.13
16182 3.68
16183 21.10
16184 0.68
Length: 16185, dtype: float64값이 잘 도출된것을 확인했다.
이를 df_bus_card에 잘 넣어주도록 하자.
df_bus_card["버스내체류시간(분)"] = round((df_bus_card["하차시각"] - \
df_bus_card["승차시각"]).dt.total_seconds()/60,2)
df_bus_card여기서 보이는 \ 의 경우는 줄바꿈만 해주고 다른 결과값은 바꾸지않는다.

이제 마찬가지로 기준년도, 기준월, 기준일, 기준시간, 기준시간(분) 컬럼 생성해보도록 하자.
- 기준년도
df_bus_card["기준년도"] = df_bus_card["승차시각"].dt.year
- 기준월
df_bus_card["기준월"] = df_bus_card["승차시각"].dt.month
- 기준일
df_bus_card["기준일"] = df_bus_card["승차시각"].dt.day
- 기준시간
df_bus_card["기준시간"] = df_bus_card["승차시각"].dt.hour
- 기준시간(분)
df_bus_card["기준시간(분)"] = df_bus_card["승차시각"].dt.minute
df_bus_card
이제 성공적으로 기준년도부터 기준시간(분)까지 하나의 필요한 정보로 통합이 완료됐다.
다음 게시물에서는 나머지 79개를 통합해보도록 하겠다.
'개발일지 > 데이터 분석' 카테고리의 다른 글
| 데이터분석 교통데이터 시각화 (4) | 2023.12.04 |
|---|---|
| 데이터분석 교통데이터 수집 및 가공(2) (0) | 2023.12.04 |
| python 데이터분석 CRUD 및 db연결 (4) | 2023.11.29 |
| [데이터 분석] csv파일 DB에 저장하기 (0) | 2023.11.29 |
| [데이터 분석] 데이터 수집하여 파일로 저장해보기 (4) | 2023.11.28 |



